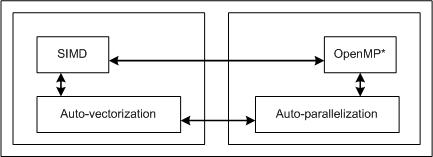
User-mandated or SIMD vectorization supplements automatic vectorization just like OpenMP* parallelization supplements automatic parallelization. The following figure illustrates this relationship. User-mandated vectorization is implemented as a single-instruction-multiple-data (SIMD) feature and is referred to as SIMD vectorization.
Note
The SIMD vectorization feature is available for both Intel® microprocessors and non-Intel microprocessors. Vectorization may call library routines that can result in additional performance gain on Intel® microprocessors than on non-Intel microprocessors. The vectorization can also be affected by certain options, such as /arch (Windows*), -m (Linux* and OS X*), or [Q]x.
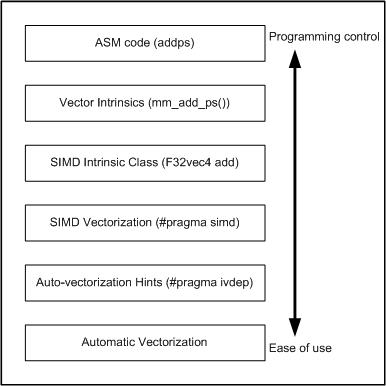
The following figure illustrates how SIMD vectorization is positioned among various approaches that you can take to generate vector code that exploits vector hardware capabilities. The programs written with SIMD vectorization are very similar to those written using auto-vectorization hints. You can use SIMD vectorization to minimize the amount of code changes that you may have to go through in order to obtain vectorized code.
SIMD vectorization uses the #pragma simd pragma to effect loop vectorization. You must add this pragma to a loop and recompile for the loop to get vectorized (the option [Q]simd is enabled by default).
Consider an example in C++ where the function add_floats() uses too many unknown pointers for the compiler’s automatic runtime independence check optimization to kick in. You can give a data dependence assertion using the auto-vectorization hint via #pragma ivdep and let the compiler decide whether the auto-vectorization optimization should be applied to the loop. Or you can now enforce vectorization of this loop by using #pragma simd .
|
Example: without #pragma simd |
|---|
[D:/simd] cat example1.c
void add_floats(float *a, float *b, float *c, float *d, float *e, int n) {
int i;
for (i=0; i<n; i++){
a[i] = a[i] + b[i] + c[i] + d[i] + e[i];
}
}
|
[D:/simd] icl example1.c –nologo -Qvec-report2 example1.c D:\simd\example1.c(3): (col. 3) remark: loop was not vectorized: existence of vector dependence. |
|
Example: with #pragma simd |
[D:/simd] cat example1.c
void add_floats(float *a, float *b, float *c, float *d, float *e, int n) {
int i;
#pragma simd
for (i=0; i<n; i++){
a[i] = a[i] + b[i] + c[i] + d[i] + e[i];
}
}
|
[D:/simd] icl example1.c -nologo -Qvec-report2 example1.c D:\simd\example1.c(4): (col. 3) remark: SIMD LOOP WAS VECTORIZED. |
The one big difference between using the SIMD pragma and auto-vectorization hints is that with the SIMD pragma, the compiler generates a warning when it is unable to vectorize the loop. With auto-vectorization hints, actual vectorization is still under the discretion of the compiler, even when you use the #pragma vector always hint.
The SIMD pragma has optional clauses to guide the compiler on how vectorization must proceed. Use these clauses appropriately so that the compiler obtains enough information to generate correct vector code. For more information on the clauses, see the #pragma simd description.
Additional Semantics
Note the following points when using #pragma simd pragma.
- A variable may belong to at most one of private, linear, or reduction (or none of them).
- Within the vector loop, an expression is evaluated as a vector value if it is private, linear, reduction, or it has a sub-expression that is evaluated to a vector value. Otherwise, it is evaluated as a scalar value (that is, broadcast the same value to all iterations). Scalar value does not necessarily mean loop invariant, although that is the most frequently seen usage pattern of scalar value.
- A vector value may not be assigned to a scalar L-value. It is an error.
- A scalar L-value may not be assigned under a vector condition. It is an error.
- The switch statement is not supported.
Note
You may find it difficult to describe vector semantics using SIMD pragma for some auto-vectorizable loops. One example is MIN/MAX reduction in C since the language does not have MIN/MAX operators.
Using vector Declaration
Consider the following C++ example code with a loop containing the math function, sinf().
Note
All code examples in this section are applicable for C/C++ on Windows* only.
|
Example: Loop with math function is auto-vectorized |
|---|
[D:/simd] cat example2.c
void vsin(float *restrict a, float *restrict b, int n) {
int i;
for (i=0; i<n; i++) {
a[i] = sinf(b[i]);
}
}
|
[D:/simd] icl example2.c –nologo –O3 -Qvec-report2 -Qrestrict example2.c D:\simd\example2.c(3): (col. 3) remark: LOOP WAS VECTORIZED. |
When you compile the above code, the loop with sinf() function is auto-vectorized using the appropriate Short Vector Math Library (SVML) library function provided by the Intel® C++ Compiler. The auto-vectorizer identifies the entry points, matches up the scalar math library function to the SVML function and invokes it.
However, within this loop if you have a call to your function, foo(), that has the same prototype as sinf(), the auto-vectorizer fails to vectorize the loop because it does not know what foo() does unless it is inlined to this call site.
|
Example: Loop with user-defined function is NOT auto-vectorized |
|---|
[D:/simd] cat example2.c
float foo(float);
void vfoo(float *restrict a, float *restrict b, int n){
int i;
for (i=0; i<n; i++){
a[i] = foo(b[i]);
}
}
|
[D:/simd] icl example2.c -nologo -O3 -Qvec-report2 -Qrestrict example2.c D:\simd\example2.c(4): (col. 3) remark: loop was not vectorized: existence of vector dependence. |
In such cases, you can use the __declspec(vector) (Windows*) or __attribute__((vector)) (Linux*) declaration to vectorize the loop. All you need to do is add the vector declaration to the function declaration, and recompile both the caller and callee code, and the loop and function are vectorized.
|
Example: Loop with user-defined function with vector declaration is vectorized |
|---|
[D:/simd] cat example3.c
// foo() and vfoo() do not have to be in the same compilation unit as long
//as both see the same declspec.
__declspec(vector)
float foo(float);
void vfoo(float *restrict a, float *restrict b, int n){
int i;
for (i=0; i<n; i++) { a[i] = foo(b[i]); }
}
float foo(float x) { ... }
|
[D:/simd] icl example3.c -nologo -O3 -Qvec-report3 –Qrestrict example3.c D:\simd\example3.c(9): (col. 3) remark: LOOP WAS VECTORIZED D:\simd\example3.c(14): (col. 3) remark: FUNCTION WAS VECTORIZED |
Restrictions on Using vector declaration
Vectorization depends on two major factors: hardware and the style of source code. When using the vector declaration, the following features are not allowed:
-
Thread creation and joining through _Cilk_spawn, _Cilk_for, OpenMP* parallel/for/sections/task, and explicit threading API calls
-
Using setjmp, longjmp, EH, SEH
-
Inline ASM code and VML
-
Calling non-vector functions (note that all SVML functions are considered vector functions)
-
Locks, barriers, atomic construct, critical sections (presumably this is a special case of the previous one).
-
Intrinsics (for example, SVML intrinsics)
-
Function call through function pointer and virtual function
-
Any loop/array notation constructs
-
Struct access
-
The switch statement
Formal parameters must be of the following data types:
- (un)signed 8, 16, 32, or 64-bit integer
- 32- or 64-bit floating point
- 64- or 128-bit complex
- a pointer (C++ reference is considered a pointer data type)