The keyword spelling is _Cilk_for. The header file <cilk/cilk.h> defines macros that allow an alternative spelling (in this case, cilk_for). This document uses the alternative spelling as defined in cilk.h.
A cilk_for loop is a replacement for the normal C/C++ for loop that permits loop iterations to run in parallel.
The general cilk_for syntax is:
cilk_for (declaration and initialization;
conditional expression;
increment expression)
body
The following rules apply to the cilk_for statement:
-
The declaration must initialize a single variable, called the loop control variable. In C++ (but not C), the variable must also be declared in the cilk_for statement, rather than before it. The constructor's syntactic form does not matter. If the variable type has a default constructor, no explicit initial value is needed.
- The conditional expression must compare the
loop control variable to a "termination expression" using one of the following comparison operators:
- <
- <=
- !=
- >=
- >
-
The termination expression and loop control variable can appear on either side of the comparison operator, but the loop control variable cannot occur within the termination expression. The termination expression value must not change from one iteration to the next.
-
The increment expression must add to or subtract from the loop control variable using one of the following supported operations:
- +=
- -=
- ++ (prefix or postfix)
- -- (prefix or postfix)
The value added to (or subtracted from) the loop control variable, like the loop termination expression, must not change from one iteration to the next.
- The body of a cilk_for loop body is executed in parallel, so it must not modify the loop control variable.
Sample cilk_for loops include:
cilk_for (int i = begin; i < end; i += 2)
f(i);
cilk_for (T::iterator i(vec.begin()); i != vec.end(); ++i)
g(i);
In C, but not C++, the loop control variable can be declared in advance:
int i;
cilk_for (i = begin; i < end; i += 2)
f(i);
cilk_for is compatible with vectorization using the simd pragma or _Simd keyword:
#pragma simd
cilk_for (int i = 0; i < N; ++i) {
// Loop body
}
cilk_for _Simd (int i = 0; i < N; ++i) {
// Loop body
}
This combination of cilk_for and use of _Simd or the simd pragma works like a SIMD loop nested within a parallel loop, with the outer loop executing chunks in parallel (using a chunk size chosen by the compiler and runtime system) and the inner loop iterating through a single chunk at a time using vectorization. When using both cilk_for and SIMD vectorization you should obey all restrictions for both constructs. If you are familiar with vectorization, but new to threading, remember that while vectorization chunks the work and operates left-to-right, it is unlikely that combined parallel/vector code will execute the chunks in that same order. In a phrase: heed the union of the restrictions to enjoy the intersection of the guarantees.
For the best results, the use of both cilk_for parallelism and SIMD vectorization should be employed only when there is a substantial amount of total work: either a significant number of iterations or a significant amount of work per iteration. In the case of nested loops, it's generally best to vectorize only the innermost loop and use cilk_for to parallelize only the one or two outermost loops. If the loops are even more deeply nested, the intermediate nesting levels should generally be serial. The parallel/vector combined loop should, therefore, be used only when the outermost and innermost loops are the same loop—that is, when there is no nesting. Ultimately, the best test of whether both methods are useful is to try a loop with and without parallelization and use a profiler to determine which way yields better performance.
The serialization of a valid Intel® Cilk™ Plus program has the same behavior as the similar C/C++ program, where the serialization of cilk_for is the result of replacing cilk_for with for. Therefore, a cilk_for loop must be a valid C/C++ for loop, but cilk_for loops have several constraints compared to C/C++ for loops.
Serial/parallel structure of cilk_for
Using cilk_for is not the same as spawning each loop iteration. In fact, the Intel compiler converts the loop body to a function that is called recursively using a divide-and-conquer strategy; this provides significantly better performance. The difference can be seen clearly in the Directed Acyclic Graph (DAG) for the two strategies.
First, consider the DAG for a cilk_for, assuming N=8 iterations and a grain size of 1. The numbers label the serial sequence of instructions, known as strands; these numbers indicate which loop iteration is handled by each strand.
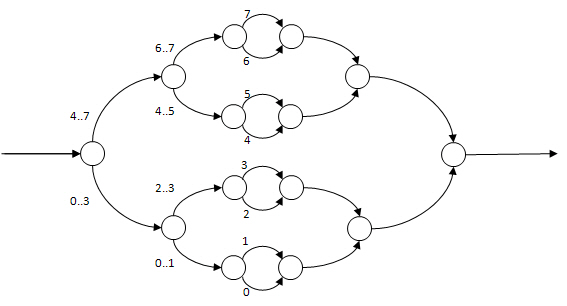
At each division of work, half of the remaining work is done in the child and half in the continuation. Importantly, the overhead of both the loop itself and of spawning new work is divided evenly along with the cost of the loop body.
If each iteration takes the same amount of time T to execute, then the span, which is the most expensive path extending from the beginning to the end of the program, is log2(N) * T, or 3 * T for 8 iterations. The run-time behavior is well balanced, regardless of the number of iterations or number of workers.
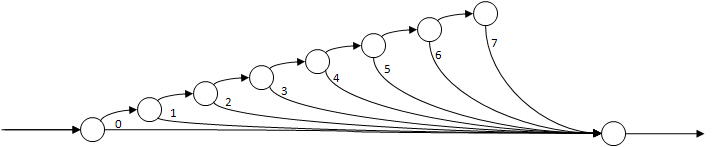
Serial/parallel structure when spawning within a serial loop
Here is the DAG for a serial loop that spawns each iteration. In this case, the work is not well balanced, because each child does the work of only one iteration before incurring the scheduling overhead inherent in entering a sync. For a short loop, or a loop in which the work in the body is much greater than the control and spawn overhead, there will be little measurable performance difference. However, for a loop of many cheap iterations, the overhead cost will overwhelm any advantage provided by parallelism.
cilk_for body
The body of a cilk_for loop defines a special region that limits the scope of cilk_for and cilk_sync statements within it. A cilk_sync statement within a cilk_for waits for completion only of the children that were spawned within the same loop iteration. It will not sync with any other iteration, nor will it sync with any other children of the surrounding function. In addition, there is an implicit cilk_sync at the end of every loop iteration (after block-scoped variable destructors are invoked). As a result, if a function has outstanding children when entering a cilk_for loop, it will have the same outstanding children when exiting the cilk_for loop. Any children that were spawned within the cilk_for loop are guaranteed to have synchronized before the loop terminates. Conversely, none of the children that existed before entering the loop will be synchronized during loop execution. This quality of a cilk_for loop can be used to your advantage (see Exception Handling).
If an exception is thrown from within a cilk_for loop body (and not handled within the same iteration), then some of the loop iterations may not run. Unlike a serial execution, it is not completely predictable which iterations will run and which will not. No iteration (other than the one throwing the exception) is aborted in the middle.
Windows*: There are restrictions when using Microsoft structured exception handling (specifically, the /EHa compiler option and the__try, __except, __finally and__leave extensions to C/C++). See Windows* Structured Exception Handling in Exception Handling.
cilk_for Type Requirements
With care, you may use custom C++ data types for the cilk_for control variable. For each custom data type, you need to provide some methods to help the runtime system compute the loop range size so that it can be divided. Types such as integer types and STL random-access iterators have an integral difference type already, and so require no additional work.
Suppose the control variable is declared with type variable_type and the loop termination expression has type termination_type, as shown here:
extern termination_type end; extern int incr; cilk_for (variable_type var; var != end; var += incr) ;
You must provide one or two functions to tell the compiler how many times the loop executes; these functions allow the compiler to compute the integer difference between variable_type and termination_type variables:
difference_type operator-(termination_type, variable_type);
difference_type operator-(variable_type, termination_type);
The following applies:
-
The argument types need not be exact, but must be convertible from termination_type or variable_type.
-
The first form of operator- is required if the loop could count up; the second is required if the loop could count down.
-
The arguments may be passed by const reference or value.
-
The program will call one or the other function at run time depending on whether the increment is positive or negative.
-
You can pick any integral type as the difference_type return value, but it must be the same for both functions.
-
It does not matter if the difference_type is signed or unsigned.
Also, you need to tell the system how to add to the control variable by defining:
variable_type::operator+=(difference_type);
If you wrote -= or -- instead of += or ++ in the loop, define operator-= instead of operator+=.
These operator functions must be consistent with ordinary arithmetic. The compiler assumes that adding one twice is the same as adding two once, and if
X - Y == 10
then
Y + 10 == X
cilk_for Restrictions
In order to parallelize a loop using the divide and conquer technique, the compiler must pre-compute the total number of iterations and must be able to pre-compute the value of the loop control variable at every iteration. To enable this computation, the control variable must act as an integer with respect to addition, subtraction, and comparison, even if it is a user-defined type. Integers, pointers, and random access iterators from the standard template library all have integer behavior and thus satisfy this requirement.
In addition, a cilk_for loop has the following limitations, which are not present for a standard C/C++ for loop. The compiler will report an error or warning for violations of the following.
-
There must be exactly one loop control variable, and the loop initialization clause must assign the value. The following form is not supported:
cilk_for (unsigned int i, j = 42; j < 1; i++, j++)
-
The loop control variable must not be modified in the loop body. The following form is not supported:
cilk_for (unsigned int i = 1; i < 16; ++i) i = f();
-
The termination and increment values are evaluated once before starting the loop and will not be re-evaluated at each iteration. Therefore, modifying either value within the loop body will not add or remove iterations. The following form is not supported:
cilk_for (unsigned int i = 1; i < x; ++i) x = f();
-
In C++, the control variable must be declared in the loop header, not outside the loop. The following form is supported for C, but not C++:
int i; cilk_for (i = 0; i < 100; i++)
-
A break or return statement will not work within the body of a cilk_for loop; the compiler will generate an error message.
-
A goto can only be used within the body of a cilk_for loop if the target is within the loop body. The compiler will generate an error message if there is a goto transfer into or out of a cilk_for loop body. Similarly, a goto cannot jump into the body of a cilk_for loop from outside the loop.
- A
cilk_for loop may not "wrap around." For example, in C/C++ you can write:
for (unsigned int i = 0; i != 1; i += 3);
and this has well-defined, if surprising, behavior. It means execute the loop 2,863,311,531 times. Such a loop produces unpredictable results when converted to a cilk_for loop.
-
A cilk_for loop may not be an infinite loop such as:
cilk_for (unsigned int i = 0; i != i; i += 0);
cilk_for Grain Size
The cilk_for statement divides the loop into chunks containing one or more loop iterations. Each chunk is executed serially, and is spawned as a chunk during the execution of the loop. The maximum number of iterations in each chunk is the grain size.
In a loop with many iterations, a relatively large grain size can significantly reduce overhead. Alternately, with a loop that has few iterations, a small grain size can increase the parallelism of the program and thus improve performance as the number of processors increases.
Setting the Grain Size
Use the cilk grainsize pragma to specify the grain size for one cilk_for loop:
#pragma cilk grainsize = expression
For example, you can write:
#pragma cilk grainsize = 1
cilk_for (int i=0; i<IMAX; ++i) { . . . }
If you do not specify a grain size, the system calculates a default that works well for most loops. The default value is set as if the following pragma were in effect:
#pragma cilk grainsize = min(2048, N / (8*p))
where N is the number of loop iterations, and p is the number of workers created during the current program run. This formula will generate parallelism of at least 8 and at most 2048. For loops with few iterations (less than 8 * workers) the grain size will be set to 1, and each loop iteration may run in parallel. For loops with more than (16484 * p) iterations, the grain size will be set to 2048.
The cilk grainsize pragma is usually used to reduce the grain size (often to 1) for particularly large loops or loops where the amount of work varies widely between iterations. Smaller grain sizes increase parallelism and improve load balancing, at the cost of increased scheduling and function-call overhead.
The cilk grainsize pragma can also be used to increase the grain size and thus, reduce overhead, especially when the loop body is short. However, once the grain size reaches about 1000 to 2000 iterations, the overhead of the cilk_for becomes inconsequential, even when the amount of work per iteration is very small. At that point, there is no benefit to increasing the grain size any further. In fact, using a grain size that is too large will reduce parallelism and impede load balancing. In general, the larger and more unbalanced the loop iterations, the smaller the grain size should be.
If you specify a grain size of zero, the default formula will be used. The result is undefined if you specify a grain size less than zero.
The expression in the pragma is evaluated at run time. For example, here is an example that sets the grain size based on the number of workers:
#pragma cilk grainsize = n/(4*__cilkrts_get_nworkers())
Loop Partitioning at Run Time
The number of chunks that are executed is approximately the number of iterations N divided by the grain size K.
The Intel compiler generates a divide and conquer recursion to execute the loop. In pseudo-code, the control structure looks like this:
void run_loop(first, last)
{
if (last - first) < grainsize)
{
for (int i=first; i<last ++i) LOOP_BODY;
}
else
{
int mid = (last+first)/2;
cilk_spawn run_loop(first, mid);
run_loop(mid, last);
}
}
In other words, the loop is split in half repeatedly until the chunk remaining is less than or equal to the grain size. The actual number of iterations run as a chunk will often be less than the grain size.
For example, consider a cilk_for loop of 16 iterations:
cilk_for (int i=0; i<16; ++i) { ... }
With grain size of 4, this will execute exactly 4 chunks of 4 iterations each. However, if the grain size is set to 5, the division will result in 4 unequal chunks consisting of 5, 3, 5 and 3 iterations.
If you work through the algorithm in detail, you will see that for the same loop of 16 iterations, a grain size of 2 and 3 will both result in exactly the same partitioning of 8 chunks of 2 iterations each.
Selecting a Good Grain Size Value
The default grain size usually performs well. Use the following guidelines to select a different value:
-
If the amount of work per iteration varies widely and if the longer iterations are likely to be unevenly distributed, it might make sense to reduce the grain size. This will decrease the likelihood that there is a time-consuming chunk that continues after other chunks have completed, which would result in idle workers with no work to steal.
-
If the amount of work per iteration is uniformly small, then it might make sense to increase the grain size. However, the default usually works well in these cases, and you don't want to risk reducing parallelism.
-
If you change the grain size, carry out performance testing to ensure that you have made the loop faster, not slower.