The Intel® runtime library has the ability to bind OpenMP* threads to physical processing units. The interface is controlled using the KMP_AFFINITY environment variable. Depending on the system (machine) topology, application, and operating system, thread affinity can have a dramatic effect on the application speed.
Thread affinity restricts execution of certain threads (virtual execution units) to a subset of the physical processing units in a multiprocessor computer. Depending upon the topology of the machine, thread affinity can have a dramatic effect on the execution speed of a program.
Thread affinity is supported on Windows* systems and versions of Linux* systems that have kernel support for thread affinity, but is not supported by OS X*.
The Intel OpenMP runtime library has the ability to bind OpenMP* threads to physical processing units. There are three types of interfaces you can use to specify this binding, which are collectively referred to as the Intel OpenMP Thread Affinity Interface:
-
The high-level affinity interface uses an environment variable to determine the machine topology and assigns OpenMP* threads to the processors based upon their physical location in the machine. This interface is controlled entirely by the KMP_AFFINITY environment variable.
-
The mid-level affinity interface uses an environment variable to explicitly specifies which processors (labeled with integer IDs) are bound to OpenMP* threads. This interface provides compatibility with the gcc* GOMP_AFFINITY environment variable, but you can also invoke it by using the KMP_AFFINITY environment variable. The GOMP_AFFINITY environment variable is supported on Linux* systems only, but users on Windows* or Linux* systems can use the similar functionality provided by the KMP_AFFINITY environment variable.
-
The low-level affinity interface uses APIs to enable OpenMP* threads to make calls into the OpenMP* runtime library to explicitly specify the set of processors on which they are to be run. This interface is similar in nature to sched_setaffinity and related functions on Linux* systems or to SetThreadAffinityMask and related functions on Windows* systems. In addition, you can specify certain options of the KMP_AFFINITY environment variable to affect the behavior of the low-level API interface. For example, you can set the affinity type KMP_AFFINITY to disabled, which disables the low-level affinity interface, or you could use the KMP_AFFINITY or GOMP_AFFINITY environment variables to set the initial affinity mask, and then retrieve the mask with the low-level API interface.
The following terms are used in this section:
-
The total number of processing elements on the machine is referred to as the number of OS thread contexts.
-
Each processing element is referred to as an Operating System processor, or OS proc.
-
Each OS processor has a unique integer identifier associated with it, called an OS proc ID.
-
The term package refers to a single or multi-core processor chip.
-
The term OpenMP* Global Thread ID (GTID) refers to an integer which uniquely identifies all threads known to the Intel OpenMP runtime library. The thread that first initializes the library is given GTID 0. In the normal case where all other threads are created by the library and when there is no nested parallelism, then n-threads-var - 1 new threads are created with GTIDs ranging from 1 to ntheads-var - 1, and each thread's GTID is equal to the OpenMP* thread number returned by function omp_get_thread_num(). The high-level and mid-level interfaces rely heavily on this concept. Hence, their usefulness is limited in programs containing nested parallelism. The low-level interface does not make use of the concept of a GTID, and can be used by programs containing arbitrarily many levels of parallelism.
Some environment variables are available for both Intel® microprocessors and non-Intel microprocessors, but may perform additional optimizations for Intel® microprocessors than for non-Intel microprocessors.
The KMP_AFFINITY Environment Variable
Note
You must set the KMP_AFFINITY environment variable before the first parallel region, or certain API calls including omp_get_max_threads(), omp_get_num_procs() and any affinity API calls, as described in Low Level Affinity API, below.
The KMP_AFFINITY environment variable uses the following general syntax:
|
Syntax |
|---|
|
KMP_AFFINITY=[<modifier>,...]<type>[,<permute>][,<offset>] |
For example, to list a machine topology map, specify KMP_AFFINITY=verbose,none to use a modifier of verbose and a type of none.
The following table describes the supported specific arguments.
|
Argument |
Default |
Description |
|---|---|---|
|
noverbose respect granularity=core |
Optional. String consisting of keyword and specifier.
The syntax for <proc-list> is explained in mid-level affinity interface. |
|
|
none |
Required string. Indicates the thread affinity to use.
The logical and physical types are deprecated but supported for backward compatibility. |
|
|
0 |
Optional. Positive integer value. Not valid with type values of explicit, none, or disabled. |
|
|
0 |
Optional. Positive integer value. Not valid with type values of explicit, none, or disabled. |
Affinity Types
Type is the only required argument.
type = none (default)
Does not bind OpenMP* threads to particular thread contexts; however, if the operating system supports affinity, the compiler still uses the OpenMP* thread affinity interface to determine machine topology. Specify KMP_AFFINITY=verbose,none to list a machine topology map.
type = balanced
Places threads on separate cores until all cores have at least one thread, similar to the scatter type. However, when the runtime must use multiple hardware thread contexts on the same core, the balanced type ensures that the OpenMP* thread numbers are close to each other, which scatter does not do. This affinity type is particularly useful on the Intel® MIC Architecture. It is supported on the CPU only for single socket systems.
Note
The OpenMP* environment variable OMP_PROC_BIND=spread is similar to KMP_AFFINITY=balanced and is available on all platforms, including multi-socket CPU systems.
type = compact
Specifying compact assigns the OpenMP* thread <n>+1 to a free thread context as close as possible to the thread context where the <n> OpenMP* thread was placed. For example, in a topology map, the nearer a node is to the root, the more significance the node has when sorting the threads.
type = disabled
Specifying disabled completely disables the thread affinity interfaces. This forces the OpenMP* run-time library to behave as if the affinity interface was not supported by the operating system. This includes the low-level API interfaces such as kmp_set_affinity and kmp_get_affinity, which have no effect and will return a nonzero error code.
type = explicit
Specifying explicit assigns OpenMP* threads to a list of OS proc IDs that have been explicitly specified by using the proclist= modifier, which is required for this affinity type. See Explicitly Specifying OS Proc IDs (GOMP_CPU_AFFINITY).
type = scatter
Specifying scatter distributes the threads as evenly as possible across the entire system. scatter is the opposite of compact; so the leaves of the node are most significant when sorting through the machine topology map.
Deprecated Types: logical and physical
Types logical and physical are deprecated and may become unsupported in a future release. Both are supported for backward compatibility.
For logical and physical affinity types, a single trailing integer is interpreted as an offset specifier instead of a permute specifier. In contrast, with compact and scatter types, a single trailing integer is interpreted as a permute specifier.
-
Specifying logical assigns OpenMP* threads to consecutive logical processors, which are also called hardware thread contexts. The type is equivalent to compact, except that the permute specifier is not allowed. Thus, KMP_AFFINITY=logical,n is equivalent to KMP_AFFINITY=compact,0,n (this equivalence is true regardless of the whether or not a granularity=fine modifier is present).
-
Specifying physical assigns threads to consecutive physical processors (cores). For systems where there is only a single thread context per core, the type is equivalent to logical. For systems where multiple thread contexts exist per core, physical is equivalent to compact with a permute specifier of 1; that is, KMP_AFFINITY=physical,n is equivalent to KMP_AFFINITY=compact,1,n (regardless of the whether or not a granularity=fine modifier is present). This equivalence means that when the compiler sorts the map it should permute the innermost level of the machine topology map to the outermost, presumably the thread context level. This type does not support the permute specifier.
Examples of Types compact and scatter
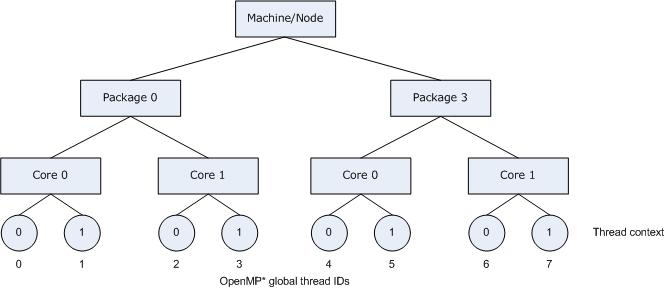
The following figure illustrates the topology for a machine with two processors, and each processor has two cores; further, each core has Hyper-Threading Technology (HT Technology) enabled.
The following figure also illustrates the binding of OpenMP* thread to hardware thread contexts when specifying KMP_AFFINITY=granularity=fine,compact.
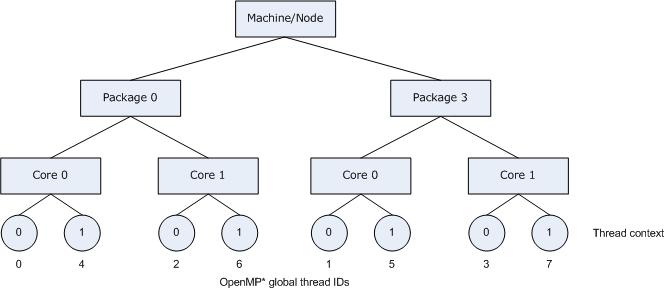
Specifying scatter on the same system as shown in the figure above, the OpenMP* threads would be assigned the thread contexts as shown in the following figure, which shows the result of specifying KMP_AFFINITY=granularity=fine,scatter.
permute and offset combinations
For both compact and scatter, permute and offset are allowed; however, if you specify only one integer, the compiler interprets the value as a permute specifier. Both permute and offset default to 0.
The permute specifier controls which levels are most significant when sorting the machine topology map. A value for permute forces the mappings to make the specified number of most significant levels of the sort the least significant, and it inverts the order of significance. The root node of the tree is not considered a separate level for the sort operations.
The offset specifier indicates the starting position for thread assignment.
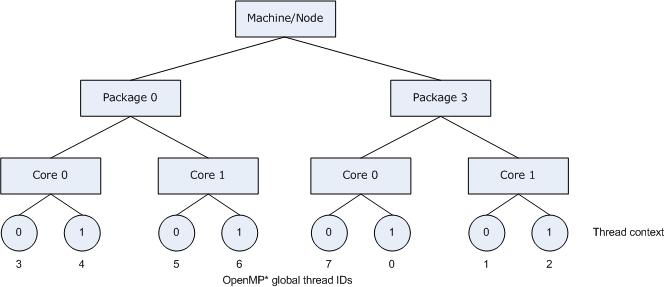
The following figure illustrates the result of specifying KMP_AFFINITY=granularity=fine,compact,0,3.
Consider the hardware configuration from the previous example, running an OpenMP* application which exhibits data sharing between consecutive iterations of loops. We would therefore like consecutive threads to be bound close together, as is done with KMP_AFFINITY=compact, so that communication overhead, cache line invalidation overhead, and page thrashing are minimized. Now, suppose the application also had a number of parallel regions which did not utilize all of the available OpenMP* threads. It is desirable to avoid binding multiple threads to the same core and leaving other cores not utilized, since a thread normally executes faster on a core where it is not competing for resources with another active thread on the same core. Since a thread normally executes faster on a core where it is not competing for resources with another active thread on the same core, you might want to avoid binding multiple threads to the same core while leaving other cores unused. The following figure illustrates this strategy of using KMP_AFFINITY=granularity=fine,compact,1,0 as a setting.
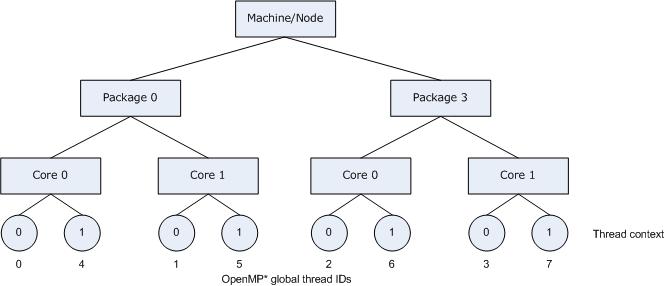
The OpenMP* thread n+1 is bound to a thread context as close as possible to OpenMP* thread n, but on a different core. Once each core has been assigned one OpenMP* thread, the subsequent OpenMP* threads are assigned to the available cores in the same order, but they are assigned on different thread contexts.
Modifier Values for Affinity Types
Modifiers are optional arguments that precede type. If you do not specify a modifier, the noverbose, respect, and granularity=core modifiers are used automatically.
Modifiers are interpreted in order from left to right, and can negate each other. For example, specifying KMP_AFFINITY=verbose,noverbose,scatter is therefore equivalent to setting KMP_AFFINITY=noverbose,scatter, or just KMP_AFFINITY=scatter.
modifier = noverbose (default)
Does not print verbose messages.
modifier = verbose
Prints messages concerning the supported affinity. The messages include information about the number of packages, number of cores in each package, number of thread contexts for each core, and OpenMP* thread bindings to physical thread contexts.
Information about binding OpenMP* threads to physical thread contexts is indirectly shown in the form of the mappings between hardware thread contexts and the operating system (OS) processor (proc) IDs. The affinity mask for each OpenMP* thread is printed as a set of OS processor IDs.
For example, specifying KMP_AFFINITY=verbose,scatter on a dual core system with two processors, with Hyper-Threading Technology (HT Technology) disabled, results in a message listing similar to the following when then program is executed:
|
Verbose, scatter message |
|---|
...
KMP_AFFINITY: Affinity capable, using global cpuid info
KMP_AFFINITY: Initial OS proc set respected:
{0,1,2,3}
KMP_AFFINITY: 4 available OS procs - Uniform topology of
KMP_AFFINITY: 2 packages x 2 cores/pkg x 1 threads/core (4 total cores)
KMP_AFFINITY: OS proc to physical thread map ([] => level not in map):
KMP_AFFINITY: OS proc 0 maps to package 0 core 0 [thread 0]
KMP_AFFINITY: OS proc 2 maps to package 0 core 1 [thread 0]
KMP_AFFINITY: OS proc 1 maps to package 3 core 0 [thread 0]
KMP_AFFINITY: OS proc 3 maps to package 3 core 1 [thread 0]
KMP_AFFINITY: Internal thread 0 bound to OS proc set {0}
KMP_AFFINITY: Internal thread 2 bound to OS proc set {2}
KMP_AFFINITY: Internal thread 3 bound to OS proc set {3}
KMP_AFFINITY: Internal thread 1 bound to OS proc set {1}
|
The verbose modifier generates several standard, general messages. The following table summarizes how to read the messages.
|
Message String |
Description |
|---|---|
|
"affinity capable" |
Indicates that all components (compiler, operating system, and hardware) support affinity, so thread binding is possible. |
|
"using global cpuid info" |
Indicates that the machine topology was discovered by binding a thread to each operating system processor and decoding the output of the cpuid instruction. |
|
"using local cpuid info" |
Indicates that compiler is decoding the output of the cpuid instruction, issued by only the initial thread, and is assuming a machine topology using the number of operating system processors. |
|
"using /proc/cpuinfo" |
Linux* only. Indicates that cpuinfo is being used to determine machine topology. |
|
"using flat" |
Operating system processor ID is assumed to be equivalent to physical package ID. This method of determining machine topology is used if none of the other methods will work, but may not accurately detect the actual machine topology. |
|
"uniform topology of" |
The machine topology map is a full tree with no missing leaves at any level. |
The mapping from the operating system processors to thread context ID is printed next. The binding of OpenMP* thread context ID is printed next unless the affinity type is none. The thread level is contained in brackets (in the listing shown above). This implies that there is no representation of the thread context level in the machine topology map. For more information, see Determining Machine Topology.
modifier = granularity
Binding OpenMP* threads to particular packages and cores will often result in a performance gain on systems with Intel processors with Intel® Hyper-Threading Technology (Intel® HT Technology) enabled; however, it is usually not beneficial to bind each OpenMP* thread to a particular thread context on a specific core. Granularity describes the lowest levels that OpenMP* threads are allowed to float within a topology map.
This modifier supports the following additional specifiers.
|
Specifier |
Description |
|---|---|
|
core |
Default. Broadest granularity level supported. Allows all the OpenMP* threads bound to a core to float between the different thread contexts. |
|
fine or thread |
The finest granularity level. Causes each OpenMP* thread to be bound to a single thread context. The two specifiers are functionally equivalent. |
Specifying KMP_AFFINITY=verbose,granularity=core,compact on the same dual core system with two processors as in the previous section, but with HT Technology enabled, results in a message listing similar to the following when the program is executed:
|
Verbose, granularity=core,compact message |
|---|
KMP_AFFINITY: Affinity capable, using global cpuid info
KMP_AFFINITY: Initial OS proc set respected:
{0,1,2,3,4,5,6,7}
KMP_AFFINITY: 8 available OS procs - Uniform topology of
KMP_AFFINITY: 2 packages x 2 cores/pkg x 2 threads/core (4 total cores)
KMP_AFFINITY: OS proc to physical thread map ([] => level not in map):
KMP_AFFINITY: OS proc 0 maps to package 0 core 0 thread 0
KMP_AFFINITY: OS proc 4 maps to package 0 core 0 thread 1
KMP_AFFINITY: OS proc 2 maps to package 0 core 1 thread 0
KMP_AFFINITY: OS proc 6 maps to package 0 core 1 thread 1
KMP_AFFINITY: OS proc 1 maps to package 3 core 0 thread 0
KMP_AFFINITY: OS proc 5 maps to package 3 core 0 thread 1
KMP_AFFINITY: OS proc 3 maps to package 3 core 1 thread 0
KMP_AFFINITY: OS proc 7 maps to package 3 core 1 thread 1
KMP_AFFINITY: Internal thread 0 bound to OS proc set {0,4}
KMP_AFFINITY: Internal thread 1 bound to OS proc set {0,4}
KMP_AFFINITY: Internal thread 2 bound to OS proc set {2,6}
KMP_AFFINITY: Internal thread 3 bound to OS proc set {2,6}
KMP_AFFINITY: Internal thread 4 bound to OS proc set {1,5}
KMP_AFFINITY: Internal thread 5 bound to OS proc set {1,5}
KMP_AFFINITY: Internal thread 6 bound to OS proc set {3,7}
KMP_AFFINITY: Internal thread 7 bound to OS proc set {3,7}
|
The affinity mask for each OpenMP* thread is shown in the listing (above) as the set of operating system processor to which the OpenMP* thread is bound.
The following figure illustrates the machine topology map, for the above listing, with OpenMP* thread bindings.
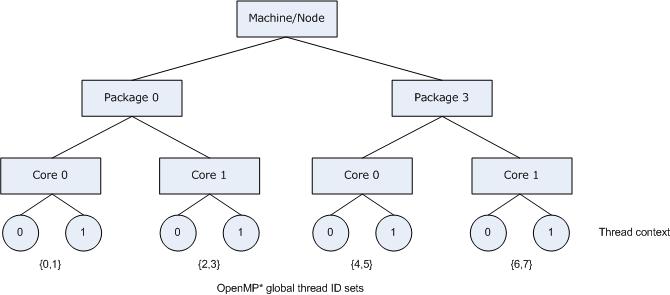
In contrast, specifying KMP_AFFINITY=verbose,granularity=fine,compact or KMP_AFFINITY=verbose,granularity=thread,compact binds each OpenMP* thread to a single hardware thread context when the program is executed:
|
Verbose, granularity=fine,compact message |
|---|
KMP_AFFINITY: Affinity capable, using global cpuid info
KMP_AFFINITY: Initial OS proc set respected:
{0,1,2,3,4,5,6,7}
KMP_AFFINITY: 8 available OS procs - Uniform topology of
KMP_AFFINITY: 2 packages x 2 cores/pkg x 2 threads/core (4 total cores)
KMP_AFFINITY: OS proc to physical thread map ([] => level not in map):
KMP_AFFINITY: OS proc 0 maps to package 0 core 0 thread 0
KMP_AFFINITY: OS proc 4 maps to package 0 core 0 thread 1
KMP_AFFINITY: OS proc 2 maps to package 0 core 1 thread 0
KMP_AFFINITY: OS proc 6 maps to package 0 core 1 thread 1
KMP_AFFINITY: OS proc 1 maps to package 3 core 0 thread 0
KMP_AFFINITY: OS proc 5 maps to package 3 core 0 thread 1
KMP_AFFINITY: OS proc 3 maps to package 3 core 1 thread 0
KMP_AFFINITY: OS proc 7 maps to package 3 core 1 thread 1
KMP_AFFINITY: Internal thread 0 bound to OS proc set {0}
KMP_AFFINITY: Internal thread 1 bound to OS proc set {4}
KMP_AFFINITY: Internal thread 2 bound to OS proc set {2}
KMP_AFFINITY: Internal thread 3 bound to OS proc set {6}
KMP_AFFINITY: Internal thread 4 bound to OS proc set {1}
KMP_AFFINITY: Internal thread 5 bound to OS proc set {5}
KMP_AFFINITY: Internal thread 6 bound to OS proc set {3}
KMP_AFFINITY: Internal thread 7 bound to OS proc set {7}
|
The OpenMP* to hardware context binding for this example was illustrated in the first example.
Specifying granularity=fine will always cause each OpenMP* thread to be bound to a single OS processor. This is equivalent to granularity=thread, currently the finest granularity level.
modifier = respect (default)
Respect the process' original affinity mask, or more specifically, the affinity mask in place for the thread that initializes the OpenMP* run-time library. The behavior differs between Linux* and Windows*:
-
On Windows*: Respect original affinity mask for the process.
-
On Linux*: Respect the affinity mask for the thread that initializes the OpenMP* run-time library.
Specifying KMP_AFFINITY=verbose,compact for the same system used in the previous example, with HT Technology enabled, and invoking the library with an initial affinity mask of {4,5,6,7} (thread context 1 on every core) causes the compiler to model the machine as a dual core, two-processor system with HT Technology disabled.
|
Verbose,compact message |
|---|
KMP_AFFINITY: Affinity capable, using global cpuid info
KMP_AFFINITY: Initial OS proc set respected:
{4,5,6,7}
KMP_AFFINITY: 4 available OS procs - Uniform topology of
KMP_AFFINITY: 2 packages x 2 cores/pkg x 1 threads/core (4 total cores)
KMP_AFFINITY: OS proc to physical thread map ([] => level not in map):
KMP_AFFINITY: OS proc 4 maps to package 0 core 0 [thread 1]
KMP_AFFINITY: OS proc 6 maps to package 0 core 1 [thread 1]
KMP_AFFINITY: OS proc 5 maps to package 3 core 0 [thread 1]
KMP_AFFINITY: OS proc 7 maps to package 3 core 1 [thread 1]
KMP_AFFINITY: Internal thread 0 bound to OS proc set {4}
KMP_AFFINITY: Internal thread 1 bound to OS proc set {6}
KMP_AFFINITY: Internal thread 2 bound to OS proc set {5}
KMP_AFFINITY: Internal thread 3 bound to OS proc set {7}
KMP_AFFINITY: Internal thread 4 bound to OS proc set {4}
KMP_AFFINITY: Internal thread 5 bound to OS proc set {6}
KMP_AFFINITY: Internal thread 6 bound to OS proc set {5}
KMP_AFFINITY: Internal thread 7 bound to OS proc set {7}
|
Because there are eight thread contexts on the machine, by default the compiler created eight threads for an OpenMP* parallel construct.
The brackets around thread 1 indicate that the thread context level is ignored, and is not present in the topology map. The following figure illustrates the corresponding machine topology map.
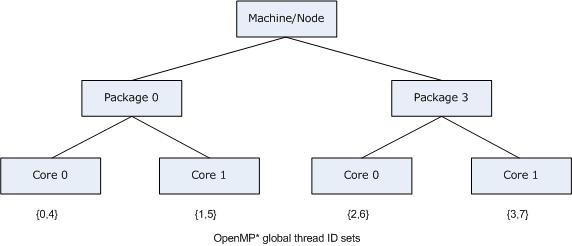
When using the local cpuid information to determine the machine topology, it is not always possible to distinguish between a machine that does not support Hyper-Threading Technology (HT Technology) and a machine that supports it, but has it disabled. Therefore, the compiler does not include a level in the map if the elements (nodes) at that level had no siblings, with the exception that the package level is always modeled. As mentioned earlier, the package level will always appear in the topology map, even if there only a single package in the machine.
modifier = norespect
Do not respect original affinity mask for the process. Binds OpenMP* threads to all operating system processors.
In early versions of the OpenMP* run-time library that supported only the physical and logical affinity types, norespect was the default and was not recognized as a modifier.
The default was changed to respect when types compact and scatter were added; therefore, thread bindings for the logical and physical affinity types may have changed with the newer compilers in situations where the application specified a partial initial thread affinity mask.
modifier = nowarnings
Do not print warning messages from the affinity interface.
modifier = warnings (default)
Print warning messages from the affinity interface (default).
Determining Machine Topology
On IA-32 and Intel® 64 architecture systems, if the package has an APIC (Advanced Programmable Interrupt Controller), the compiler will use the cpuid instruction to obtain the package id, core id, and thread context id. Under normal conditions, each thread context on the system is assigned a unique APIC ID at boot time. The compiler obtains other pieces of information obtained by using the cpuid instruction, which together with the number of OS thread contexts (total number of processing elements on the machine), determine how to break the APIC ID down into the package ID, core ID, and thread context ID.
There are two ways to specify the APIC ID in the cpuid instruction - the legacy method in leaf 4, and the more modern method in leaf 11. Only 256 unique APIC IDs are available in leaf 4. Leaf 11 has no such limitation.
Normally, all core ids on a package and all thread context ids on a core are contiguous; however, numbering assignment gaps are common for package ids, as shown in the figure above.
If the compiler cannot determine the machine topology using any other method, but the operating system supports affinity, a warning message is printed, and the topology is assumed to be flat. For example, a flat topology assumes the operating system process N maps to package N, and there exists only one thread context per core and only one core for each package.
If the machine topology cannot be accurately determined as described above, the user can manually copy /proc/cpuinfo to a temporary file, correct any errors, and specify the machine topology to the OpenMP* runtime library via the environment variable KMP_CPUINFO_FILE=<temp_filename>, as described in the section KMP_CPUINFO_FILE and /proc/cpuinfo.
Regardless of the method used in determining the machine topology, if there is only one thread context per core for every core on the machine, the thread context level will not appear in the topology map. If there is only one core per package for every package in the machine, the core level will not appear in the machine topology map. The topology map need not be a full tree, because different packages may contain a different number of cores, and different cores may support a different number of thread contexts.
The package level will always appear in the topology map, even if there only a single package in the machine.
KMP_CPUINFO_FILE and /proc/cpuinfo
One of the methods the Intel® C++ Compiler OpenMP runtime library can use to detect the machine topology on Linux* systems is to parse the contents of /proc/cpuinfo. If the contents of this file (or a device mapped into the Linux* file system) are insufficient or erroneous, you can consider copying its contents to a writable temporary file <temp_file>, correct it or extend it with the necessary information, and set KMP_CPUINFO_FILE=<temp_file>.
If you do this, the OpenMP* runtime library will read the <temp_file> location pointed to by KMP_CPUINFO_FILE instead of the information contained in /proc/cpuinfo or attempting to detect the machine topology by decoding the APIC IDs. That is, the information contained in the <temp_file> overrides these other methods. You can use the KMP_CPUINFO_FILE interface on Windows* systems, where /proc/cpuinfo does not exist.
The content of /proc/cpuinfo or <temp_file> should contain a list of entries for each processing element on the machine. Each processor element contains a list of entries (descriptive name and value on each line). A blank line separates the entries for each processor element. Only the following fields are used to determine the machine topology from each entry, either in <temp_file> or /proc/cpuinfo:
|
Field |
Description |
|---|---|
|
processor : |
Specifies the OS ID for the processing element. The OS ID must be unique. The processor and physical id fields are the only ones that are required to use the interface. |
|
physical id : |
Specifies the package ID, which is a physical chip ID. Each package may contain multiple cores. The package level always exists in the Intel compiler OpenMP run-time library's model of the machine topology. |
|
core id : |
Specifies the core ID. If it does not exist, it defaults to 0. If every package on the machine contains only a single core, the core level will not exist in the machine topology map (even if some of the core ID fields are non-zero). |
|
thread id : |
Specifies the thread ID. If it does not exist, it defaults to 0. If every core on the machine contains only a single thread, the thread level will not exist in the machine topology map (even if some thread ID fields are non-zero). |
|
node_n id : |
This is a extension to the normal contents of /proc/cpuinfo that can be used to specify the nodes at different levels of the memory interconnect on Non-Uniform Memory Access (NUMA) systems. Arbitrarily many levels n are supported. The node_0 level is closest to the package level; multiple packages comprise a node at level 0. Multiple nodes at level 0 comprise a node at level 1, and so on. |
Each entry must be spelled exactly as shown, in lowercase, followed by optional whitespace, a colon (:), more optional whitespace, then the integer ID. Fields other than those listed are simply ignored.
Note
It is common for the thread id field to be missing from /proc/cpuinfo on many Linux* variants, and for a field labeled siblings to specify the number of threads per node or number of nodes per package. However, the Intel OpenMP runtime library ignores fields labeled siblings so it can distinguish between the thread id and siblings fields. When this situation arises, the warning message Physical node/pkg/core/thread ids not unique appears (unless the type specified is nowarnings).
Windows* Processor Groups
On a 64-bit Windows* operating system, it is possible for multiple processor groups to accommodate more than 64 processors. Each group is limited in size, up to a maximum value of sixty-four (64) processors.
If multiple processor groups are detected, the default is to model the machine as a 2-level tree, where level 0 are for the processors in a group, and level 1 are for the different groups. Threads are assigned to a group until there are as many OpenMP* threads bound to the groups as there are processors in the group. Subsequent threads are assigned to the next group, and so on.
By default, threads are allowed to float among all processors in a group, that is to say, granularity equals the group [granularity=group]. You can override this binding and explicitly use another affinity type like compact, scatter, and so on. If you do so, the granularity must be sufficiently fine to prevent a thread from being bound to multiple processors in different groups.
Using a Specific Machine Topology Modeling Method (KMP_TOPOLOGY_METHOD)
You can set the KMP_TOPOLOGY_METHOD environment variable to force OpenMP* to use a particular machine topology modeling method.
|
Value |
Description |
|---|---|
|
cpuid leaf 11 : |
Decodes the APIC identifiers as specfied by leaf 11 of the cpuid instruction. |
|
cpuid leaf 4 : |
Decodes the APIC identifiers as specified in leaf 4 of the cpuid instruction. |
|
cpuinfo : |
If KMP_CPUINFO_FILE is not specified, forces OpenMP* to parse /proc/cpuinfo to determine the topology (Linux* only). If KMP_CPUINFO_FILE is specified as described above, uses it (Windows* or Linux*). |
|
group : |
Models the machine as a 2-level map, with level 0 specifying the different processors in a group, and level 1 specifying the different groups (Windows* 64-bit only) . |
|
flat : |
Models the machine as a flat (linear) list of processors. |
Explicitly Specifying OS Processor IDs (GOMP_CPU_AFFINITY)
Note
You must set the GOMP_CPU_AFFINITY environment variable before the first parallel region, or certain API calls including omp_get_max_threads(), omp_get_num_procs() and any affinity API calls, as described in Low Level Affinity API, below.
Instead of allowing the library to detect the hardware topology and automatically assign OpenMP* threads to processing elements, the user may explicitly specify the assignment by using a list of operating system (OS) processor (proc) IDs. However, this requires knowledge of which processing elements the OS proc IDs represent.
This list may either be specified by using the proclist modifier along with the explicit affinity type in the KMP_AFFINITY environment variable, or by using the GOMP_AFFINITY environment variable (for compatibility with gcc) when using the OpenMP* Source Compatibility and Interoperability with Other Compilers.
On Linux* systems, when using the Intel OpenMP compatibility libraries enabled by the compiler option -qopenmp-lib compat, you can use the GOMP_AFFINITY environment variable to specify a list of OS processor IDs. Its syntax is identical to that accepted by libgomp (assume that <proc_list> produces the entire GOMP_AFFINITY environment string):
|
Value |
Description |
|---|---|
|
<proc_list> := |
<entry> | <elem> , <list> | <elem> <whitespace> <list> |
|
<elem> := |
<proc_spec> | <range> |
|
<proc_spec> := |
<proc_id> |
|
<range> := |
<proc_id> - <proc_id> | <proc_id> - <proc_id> : <int> |
|
<proc_id> := |
<positive_int> |
OS processors specified in this list are then assigned to OpenMP* threads, in order of OpenMP* Global Thread IDs. If more OpenMP* threads are created than there are elements in the list, then the assignment occurs modulo the size of the list. That is, OpenMP* Global Thread ID n is bound to list element n mod <list_size>.
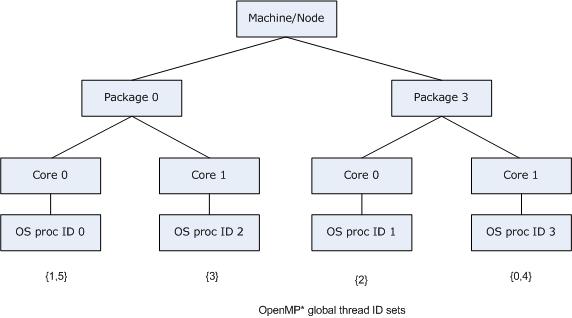
Consider the machine previously mentioned: a dual core, dual-package machine without Intel® Hyper-Threading Technology (Intel® HT Technology) enabled, where the OS proc IDs are assigned in the same manner as the example in a previous figure. Suppose that the application creates six OpenMP* threads instead of 4 (the default), oversubscribing the machine. If GOMP_AFFINITY=3,0-2, then OpenMP* threads are bound as shown in the figure below, just as should happen when compiling with gcc and linking with libgomp:
The same syntax can be used to specify the OS proc ID list in the proclist=[<proc_list>] modifier in the KMP_AFFINITY environment variable string. There is a slight difference: in order to have strictly the same semantics as in the gcc OpenMP* runtime library libgomp: the GOMP_AFFINITY environment variable implies granularity=fine. If you specify the OS proc list in the KMP_AFFINITY environment variable without a granularity= specifier, then the default granularity is not changed. That is, OpenMP* threads are allowed to float between the different thread contexts on a single core. Thus GOMP_AFFINITY=<proc_list> is an alias for KMP_AFFINITY="granularity=fine,proclist=[<proc_list>],explicit".
In the KMP_AFFINITY environment variable string, the syntax is extended to handle operating system processor ID sets. The user may specify a set of operating system processor IDs among which an OpenMP* thread may execute ("œfloat") enclosed in brackets:
|
Value |
Description |
|---|---|
|
<proc_list> := |
<proc_id> | { <float_list> } |
|
<float_list> := |
<proc_id> | <proc_id> , <float_list> |
This allows functionality similarity to the granularity= specifier, but it is more flexible. The OS processors on which an OpenMP* thread executes may exclude other OS processors nearby in the machine topology, but include other distant OS processors. Building upon the previous example, we may allow OpenMP* threads 2 and 3 to "œfloat" between OS processor 1 and OS processor 2 by using KMP_AFFINITY="granularity=fine,proclist=[3,0,{1,2},{1,2}],explicit", as shown in the figure below:
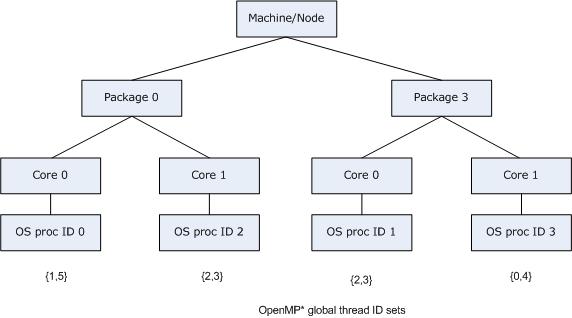
If verbose were also specified, the output when the application is executed would include:
|
KMP_AFFINITY="granularity=verbose,fine,proclist=[3,0,{1,2},{1,2}],explicit" |
|---|
KMP_AFFINITY: Affinity capable, using global cpuid info
KMP_AFFINITY: Initial OS proc set respected: {0,1,2,3}
KMP_AFFINITY: 4 available OS procs - Uniform topology of
KMP_AFFINITY: 2 packages x 2 cores/pkg x 1 threads/core (4 total cores)
KMP_AFFINITY: OS proc to physical thread map ([] => level not in map):
KMP_AFFINITY: OS proc 0 maps to package 0 core 0 [thread 0]
KMP_AFFINITY: OS proc 2 maps to package 0 core 1 [thread 0]
KMP_AFFINITY: OS proc 1 maps to package 3 core 0 [thread 0]
KMP_AFFINITY: OS proc 3 maps to package 3 core 1 [thread 0]
KMP_AFFINITY: Internal thread 0 bound to OS proc set {3}
KMP_AFFINITY: Internal thread 1 bound to OS proc set {0}
KMP_AFFINITY: Internal thread 2 bound to OS proc set {1,2}
KMP_AFFINITY: Internal thread 3 bound to OS proc set {1,2}
KMP_AFFINITY: Internal thread 4 bound to OS proc set {3}
KMP_AFFINITY: Internal thread 5 bound to OS proc set {0}}
|
Low Level Affinity API
Instead of relying on the user to specify the OpenMP* thread to OS proc binding by setting an environment variable before program execution starts (or by using the kmp_settings interface before the first parallel region is reached), each OpenMP* thread can determine the desired set of OS procs on which it is to execute and bind to them with the kmp_set_affinity API call.
Caution
When you use this affinity interface you take complete control of the hardware resources on which your threads run. To do that sensibly you need to understand in detail how the logical CPUs, the enumeration of hardware threads controlled by the OS, map to the physical hardware of the specific machine on which you are running. That mapping can be, and likely is, different on different machines, so you risk binding machine-specific information into your code, which can result in explicitly forcing bad affinities when your code runs on a different machine. And if you are concerned with optimization at this level of detail, your code is probably valuable, and therefore will probably move to another machine.
This interface may also allow you to ignore the resource limitations that were set by the program startup mechanism, such as MPI, specifically to prevent multiple OpenMP processes on the same node from using the same hardware threads. Again, this can result in explicitly forcing affinities that cause bad performance, and the OpenMP runtime will neither prevent this from happening, nor warn you when it does. These are expert interfaces and you must use them with caution.
It is recommended, therefore, to use the higher level affinity settings if you possibly can, because they are more portable and do not require this low level knowledge.
The Fortran API interfaces follow, where the type name kmp_affinity_mask_t is defined in omp_lib.h or omp_lib.mod:
Note
Some of these interfaces have offload equivalents. The offload equivalent takes two additional arguments to specify the target type and target number. For more information, see Calling Functions on the CPU to Modify the Coprocessor's Execution Environment.
|
Syntax |
Description |
|---|---|
|
integer function
kmp_set_affinity(mask) |
Sets the affinity mask for the current OpenMP* thread to mask, where mask is a set of OS proc IDs that has been created using the API calls listed below, and the thread will only execute on OS procs in the set. Returns either a zero (0) upon success or a nonzero error code. |
|
integer kmp_get_affinity(mask) |
Retrieves the affinity mask for the current OpenMP* thread, and stores it in mask, which must have previously been initialized with a call to kmp_create_affinity_mask(). Returns either a zero (0) upon success or a nonzero error code. |
|
integer function kmp_get_affinity_max_proc() |
Returns the maximum OS proc ID that is on the machine, plus 1. All OS proc IDs are guaranteed to be between 0 (inclusive) and kmp_get_affinity_max_proc() (exclusive). |
|
subroutine
kmp_create_affinity_mask(mask) |
Allocates a new OpenMP* thread affinity mask, and initializes mask to the empty set of OS procs. The implementation is free to use an object of kmp_affinity_mask_kind either as the set itself, a pointer to the actual set, or an index into a table describing the set. Do not make any assumption as to what the actual representation is. |
|
subroutine
kmp_destroy_affinity_mask(mask) |
Deallocates the OpenMP* thread affinity mask. For each call to kmp_create_affinity_mask(), there should be a corresponding call to kmp_destroy_affinity_mask(). |
|
integer function
kmp_set_affinity_mask_proc(proc, mask) |
Adds the OS proc ID proc to the set mask, if it is not already. Returns either a zero (0) upon success or a nonzero error code. |
|
integer function
kmp_unset_affinity_mask_proc(proc, mask) |
If the OS proc ID proc is in the set mask, it removes it. Returns either a zero (0) upon success or a nonzero error code. |
|
integer function
kmp_get_affinity_mask_proc(proc, mask)integer proc |
Returns 1 if the OS proc ID proc is in the set mask; if not, it returns 0. |
Once an OpenMP* thread has set its own affinity mask via a successful call to kmp_set_affinity(), then that thread remains bound to the corresponding OS proc set until at least the end of the parallel region, unless reset via a subsequent call to kmp_set_affinity().
Between parallel regions, the affinity mask (and the corresponding OpenMP* thread to OS proc bindings) can be considered thread private data objects, and have the same persistence as described in the OpenMP* Application Program Interface. For more information, see the OpenMP* API specification (http://www.openmp.org), some relevant parts of which are provided below:
In order for the affinity mask and thread binding to persist between two consecutive active parallel regions, all three of the following conditions must hold:
-
Neither parallel region is nested inside another explicit parallel region.
-
The number of threads used to execute both parallel regions is the same.
-
The value of the dyn-var internal control variable in the enclosing task region is false at entry to both parallel regions."
Therefore, by creating a parallel region at the start of the program whose sole purpose is to set the affinity mask for each thread, you can mimic the behavior of the KMP_AFFINITY environment variable with low-level affinity API calls, if program execution obeys the three aforementioned rules from the OpenMP* specification.
The following example shows how these low-level interfaces can be used. This code binds the executing thread to the specified logical CPU:
|
Example |
|---|
|
This program fragment was written with knowledge about the mapping of the OS proc IDs to the physical processing elements of the target machine. On another machine, or on the same machine with a different OS installed, the program would still run, but the OpenMP* thread to physical processing element bindings could differ and you might be explicitly force a bad distribution.