The
Intel® Data Analytics Acceleration Library
(Intel® DAAL)
is the library of Intel® Architecture optimized building blocks covering all
data analytics stages: data acquisition from a data source, preprocessing,
transformation, data mining, modeling, validation, and decision making. To
achieve best performance on a range of Intel® processors,
Intel DAAL
uses optimized algorithms from the Intel® Math Kernel Library and Intel®
Integrated Performance Primitives.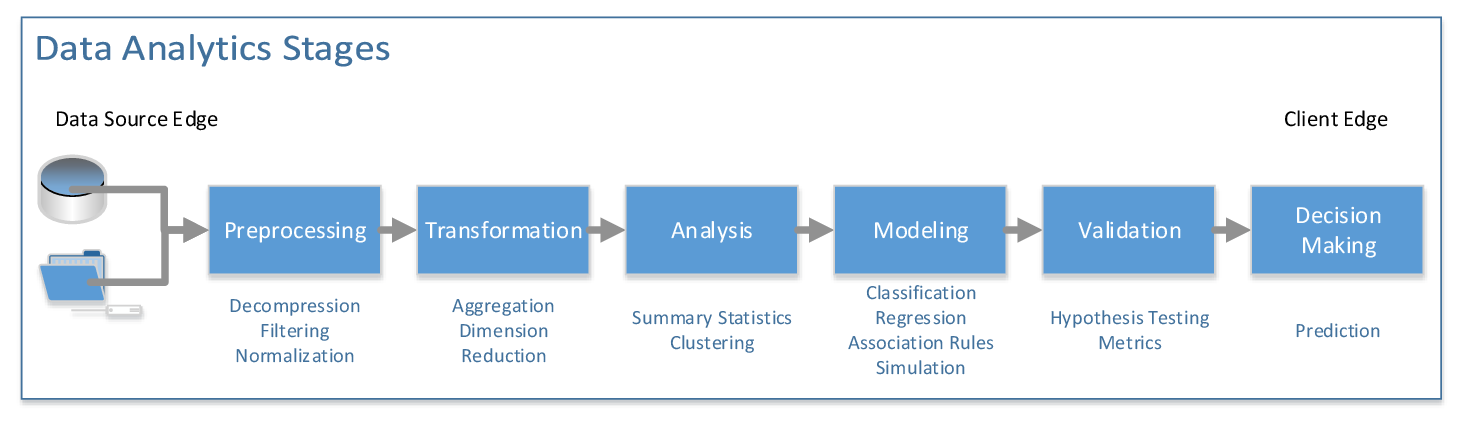
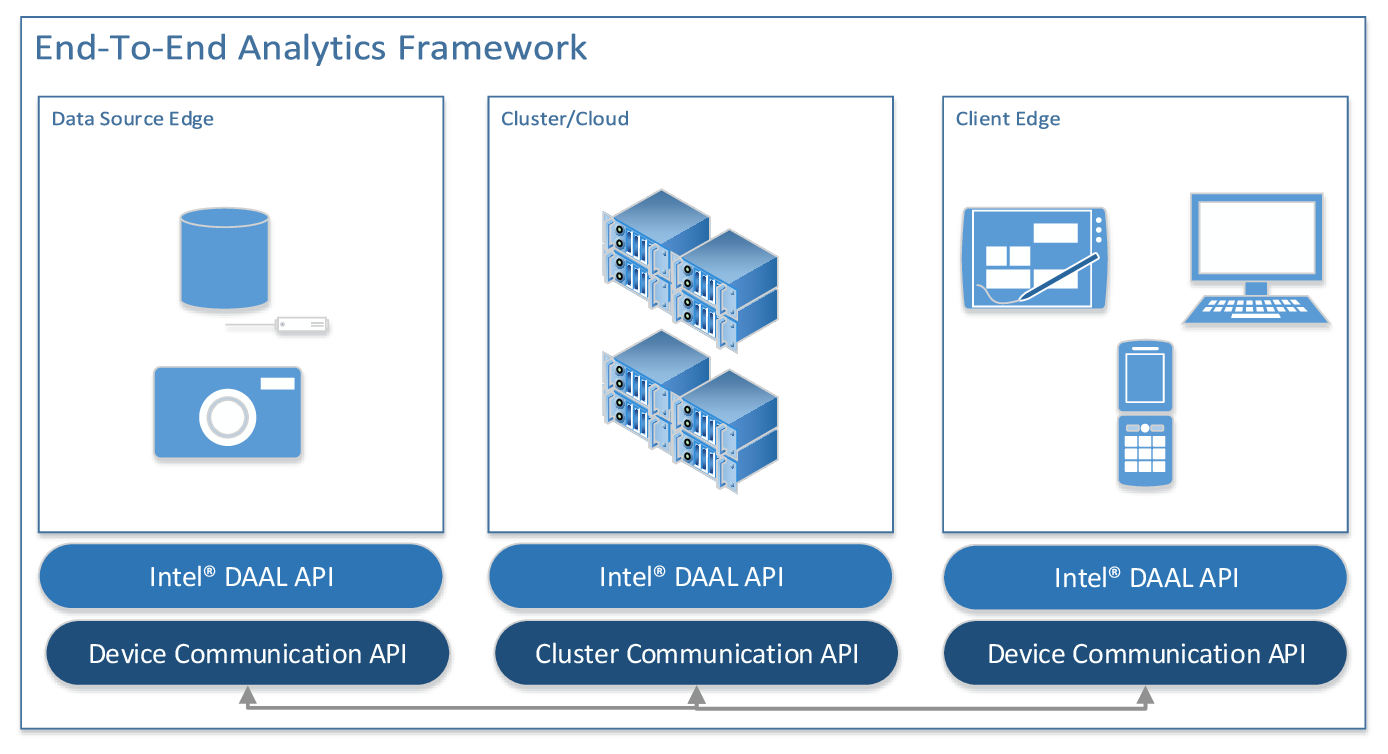
Intel DAAL
supports the concept of the end-to-end analytics when some of data analytics
stages are performed on the edge devices (close to where the data is generated
and where it is finally consumed). Specifically,
Intel DAAL
Application Programming Interfaces (APIs) are agnostic about a particular
cross-device communication technology and therefore can be used within
different end-to-end analytics frameworks.
Intel DAAL
consists of the following major components: Data Management, Algorithms, and
Services:
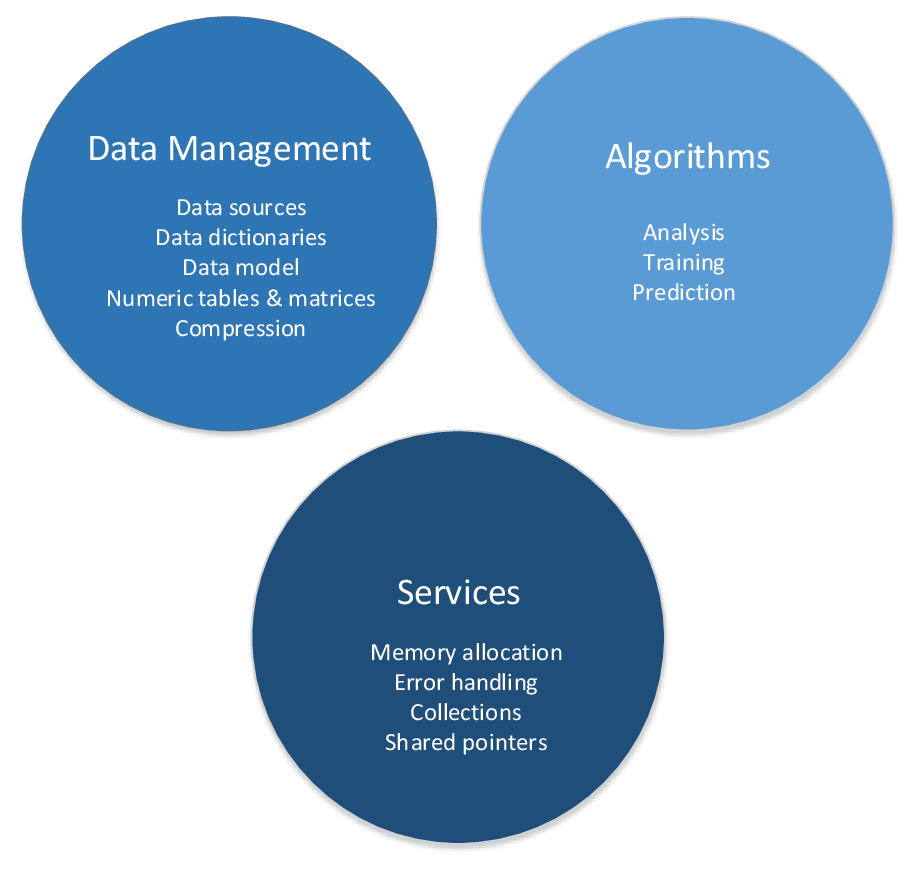
The Data Management component includes classes and utilities for data acquisition, initial preprocessing and normalization, for data conversion into numeric formats done by one of supported Data Sources, and for model representation. The NumericTable class and its derivative classes within the Data Management component are intended for in-memory numeric data manipulation. The Model class mimics the actual data and represents it in a compact way so that you can use the library when the actual data is missing, incomplete, noisy, or unavailable. These are the key interfaces for processing a data set with algorithms. The DataSourceDictionary and NumericTableDictionary classes provide generic methods for dictionary manipulation, such as accessing a particular data feature, setting and retrieving the number of features, and adding a new feature.
The Algorithms component consists of classes that implement algorithms for data analysis (data mining), and data modeling (training and prediction). These algorithms include matrix decompositions, clustering, classification, and regression algorithms, as well as association rules discovery.
Algorithms support the following computation modes:
- Batch processing
- Online processing
- Distributed processing
In the batch processing mode, the algorithm works with the entire data set to produce the final result. A more complex scenario occurs when the entire data set is not available at the moment or the data set does not fit into the device memory.
In the online processing mode, the algorithm processes a data set in blocks streamed into device memory by doing incrementally updating partial results, which are finalized upon processing of the last data block.
In the distributed processing mode, the algorithm operates on a data set distributed across several devices (compute nodes). The algorithm produces partial results on each node, which are finally merged into the final result on the master node.
Distributed algorithms in Intel DAAL are abstracted from underlying cross-device communication technology, which enables use of the library in a variety of multi-device computing and data transfer scenarios. They include but are not limited to MPI* based cluster environments, Hadoop*/Spark* based cluster environments, low-level data exchange protocols, and more.
You can find typical use cases for MPI*, Hadoop*, and Spark* in subfolders of the following folder of your product package, assuming the default installation path:
- On Linux or OS X: /opt/intel/samples_2016/en/daal
- On Windows: C:\Program files (x86)\IntelSWTools\samples_2016\en\daal
Depending on the usage, algorithms operate both on actual data (data set) and data models. Analysis algorithms typically operate on data sets. Training algorithms typically operate on a data set to train the appropriate data model. Prediction algorithms typically work with the trained data model and with a working data set.
Models produced by training algorithms are associated with interfaces for generation of metrics that characterize the models. These metrics can be used during creation of a model to understand its quality, or in a production mode to track agreement between actual data and the model that represents it.
The Services component includes classes and utilities used across Data Management and Algorithms components. These classes enable memory allocation, error handling, and implementation of collections and shared pointers. A collection enables storing different type of objects in a unified manner. In Intel DAAL, collections are used for handling the input and output of algorithms and for error handling. Intel DAAL implements shared pointers to enable memory handling needed for memory management operations such as deallocation.
Classes implemented in Data Management, Algorithms, and Services components cover most important usage scenarios and allow seamless implementation of complex data analytics workflows through direct API calls. At the same time the library is an object-oriented framework that enables you to customize the API by redefining particular classes and methods of the library.
|
Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #20110804 |