Given n feature vectors x 1= (x 11,…,x 1p ), ..., x n = (x n1,…,x n p ) of dimension p and a positive integer k, the problem is to find k p-dimensional vectors m 1,…,m k that minimize the goal function, within-cluster sum of squares
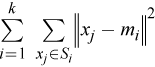
where S i is a set of vectors to which m i is the closest center. The vectors m 1,…,m k are called centroids. To start computations, the algorithm requires initial values of centroids.
Centroid Initialization
Centroid initialization can be done using these methods:
-
Choice of first k feature vectors from the data set
-
Random choice of k feature vectors from the data set using the following, simple random sampling draw-by-draw, algorithm:
Let S contain all n feature vectors from the input data sets. The algorithm does the following:
-
Chooses one of the feature vectors s i from S with equal probability
-
Excludes s i from S and adds it to the sample
-
Resumes from step 1 until the sample reaches the desired size k
-
Computation
Computation of the goal function includes computation of the Euclidean distance between vectors ||x j - m i ||. The algorithm uses the following modification of the Euclidean distance between feature vectors a and b: d(a,b) = d 1(a,b) + d 2(a,b), where d 1 is computed for continuous features as

and d 2 is computed for binary categorical features as
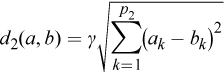
In these equations, γ weighs the impact of binary categorical features on the clustering, p 1 is the number of continuous features, and p 2 is the number of binary categorical features. Note that the algorithm does not support non-binary categorical features.
The K-Means clustering algorithm computes centroids using Lloyd's method [Lloyd82]. For each feature vector x 1,…,x n , you can also compute the index of the cluster that contains the feature vector.