The distributed processing mode assumes that the data set is split in nblocks blocks across computation nodes.
To initialize the implicit ALS algorithm in the distributed processing mode, use the one-step process illustrated by the following diagram for nblocks=3:
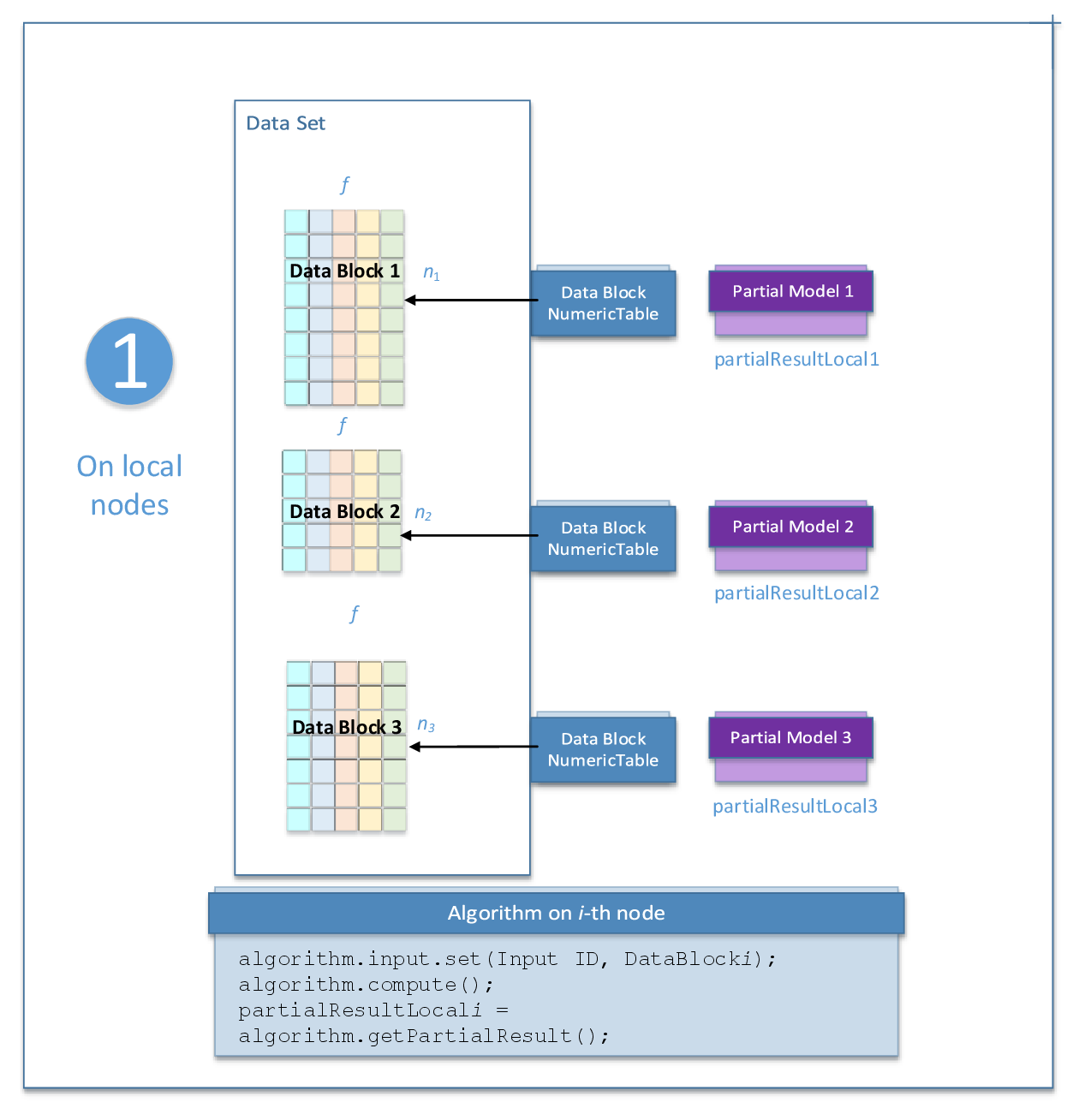
Input
In the distributed processing mode, initialization of item factors for the implicit ALS algorithm accepts the input described below. Pass the Input ID as a parameter to the methods that provide input for your algorithm. For more details, see Algorithms.
|
Input ID |
Input |
|
|---|---|---|
|
data |
Pointer to the m x n numeric table with the mining data. The input can be an object of any class derived from NumericTable except PackedTriangularMatrix and PackedSymmetricMatrix. |
|
Parameters
In the distributed processing mode, initialization of item factors for the implicit ALS algorithm has the following parameters:
|
Parameter |
Default Value |
Description |
|
|---|---|---|---|
|
algorithmFPType |
double |
The floating-point type that the algorithm uses for intermediate computations. Can be float or double. |
|
|
method |
fastCSR |
Performance-oriented computation method for CSR numeric tables, the only method supported by the algorithm. |
|
|
nFactors |
10 |
The total number of factors. |
|
|
seed |
777777 |
The seed for the random number generation in the initialization step. |
|
|
fullNUsers |
0 |
The total number of users. |
|
Output
In the distributed processing mode, initialization of item factors for the implicit ALS algorithm calculates the result described below. Pass the Result ID as a parameter to the methods that access the results of your algorithm. For more details, see Algorithms.
|
Result ID |
Result |
|
|---|---|---|
|
model |
The model with initialized item factors. The result can only be an object of the Model class. |
|