For two classes C 1 and C 2, given a vector X= (x 1, …, x n ) of class labels computed at the prediction stage of the classification algorithm and a vector Y= (y 1, …, y n ) of expected class labels, the problem is to evaluate the classifier by computing the confusion matrix and connected quality metrics: precision, recall, and so on.
Further definitions use the following notations:
tp (true positive) |
the number of correctly recognized observations for class C 1 |
tn (true negative) |
the number of correctly recognized observations that do not belong to the class C 1 |
fp (false positive) |
the number of observations that were incorrectly assigned to the class C 1 |
fn (false negative) |
the number of observations that were not recognized as belonging to the class C 1 |
The library uses the following quality metrics for binary classifiers:
|
Quality Metric |
Definition |
|---|---|
|
Accuracy |
|
|
Precision |
|
|
Recall |
|
|
F-score |
|
|
Specificity |
|
|
Area under curve (AUC) |
|
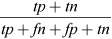
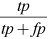
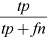
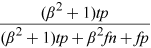
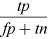
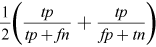
For more details of these metrics, including the evaluation focus, refer to [Sokolova09].
The confusion matrix is defined as follows:
|
Classified as Class C 1 |
Classified as Class C 2 |
|
|
Actual Class C 1 |
tp |
fn |
|
Actual Class C 2 |
fp |
tn |