Given a set X of n feature vectors x 1= (x 11,…,x 1p ), ..., x n = (x n1,…,x np ) of dimension p, the problem is to find a maximum-likelihood estimate of the parameters of the underlying distribution when the data is incomplete or has missing values.
Expectation-Maximization (EM) Algorithm in the General Form
Let X be the observed data which has log-likelihood l(θ; X) depending on the parameters θ. Let X m be the latent or missing data, so that T=(X, X m ) is the complete data with log-likelihood l 0 (θ; X). The algorithm for solving the problem in its general form is the following EM algorithm ([Dempster77], [Hastie2009]):
EM algorithm for the Gaussian Mixture Model
Gaussian Mixture Model (GMM) is a mixture of k p-dimensional multivariate Gaussian distributions represented as
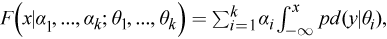
where Σ k i = 1 α i = 1 and α i ≥ 0.
The pd( x|θ i ) is the probability density function with parameters θ i = (m i , Σ i ), where m i is the vector of means, and Σ i is the variance-covariance matrix. The probability density function for a p-dimensional multivariate Gaussian distribution is defined as follows:
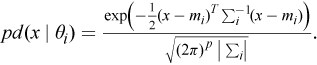
Let z ij = I{x i belongs to j mixture component} be the indicator function and θ=(α 1, ..., α k ; θ 1, ..., θ k ).
Computation
The EM algorithm for GMM includes the following steps:
Define the weights as follows:
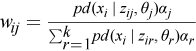
for i=1, ..., n and j=1, …, k.
-
Choose initial values of the parameters
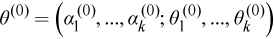
-
Expectation step: in the j-th step, compute the matrix W = (w ij ) nxk with the weights w ij
-
Maximization step: in the j-th step, for all r=1, ..., k compute:
-
The mixture weights
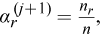
where
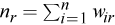
is the "amount" of the feature vectors that are assigned to the r-th mixture component
-
Mean estimates
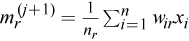
-
Covariance estimate
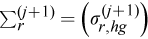
of size p x p with
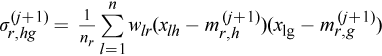
-
- Repeat steps
2
and
3
until any of these conditions is met:
-
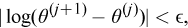
where the likelihood function is
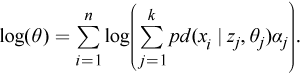
-
The number of iterations exceeds the predefined level.
-
Initialization
The EM algorithm for GMM requires initialized vector of weights, vectors of means, and variance-covariance [Biernacki2003, Maitra2009].
The EM initialization algorithm for GMM includes the following steps:
-
Perform nTrials starts of the EM algorithm with nIterations iterations and start values:
-
Initial means - k different random observations from the input data set
-
Initial weights - the values of 1/k
-
Initial covariance matrices - the covariance of the input data
-
-
Regard the result of the best EM algorithm in terms of the likelihood function values as the result of initialization