Intel® VTune™ Amplifier provides a mechanism to analyze code parallelism and power consumption using the hardware event-based sampling with the stack collection enabled. As soon as you created a VTune Amplifier project and specified your analysis target, follow these steps to enable the collection and analyze the data:
Configure and run an analysis.
VTune Amplifier runs the target, collects the hardware event-based stack sampling data, and opens the result.
Configure Analysis
Click the
 New Analysis button on the VTune Amplifier toolbar.
New Analysis button on the VTune Amplifier toolbar.
The Analysis Type configuration window opens.
From the analysis tree on the right, choose the required event-based sampling analysis type. Typically, you are recommended to start with the Advanced Hotspots analysis.
The right pane is updated with the configuration options for the selected analysis type.
Configure the analysis options:
For Advanced Hotspots, select the Hotspots and stacks (recommended) or Hotspots, call counts and stacks collection level.
For other hardware event-based sampling analysis types, select the Collect stacks checkbox.
Click the Start button on the right to run the selected analysis type.
VTune Amplifier collects hardware event-based sampling data along with the information on execution paths. You may see the collected results in the Hardware Events viewpoint providing performance, parallelism and power consumption data on detected call paths.
Note
You may also select the Estimate call counts checkbox to statistically approximate the number of calls to sampled functions.
The event-based stack sampling data collection cannot be configured for the entire system. You have to specify an application to launch or attach to.
Call stack analysis adds an overhead to your data collection. To minimize the overhead incurred with the stack size, use the Stack size option in the custom hardware event-based sampling configuration or -stack-size knob from CLI to limit the size of a raw stack. By default, a full stack is collected. If you disable this option, the overhead will be also reduced but no stack data will be collected.
Collect Data
Multitask operating systems execute all software threads in time slices (thread execution quanta). Intel® VTune™ Amplifier profiler handles thread quantum switches and performs all monitoring operations in correlation with the thread quantum layout.
The figure below explains the general idea of per-thread quantum monitoring:
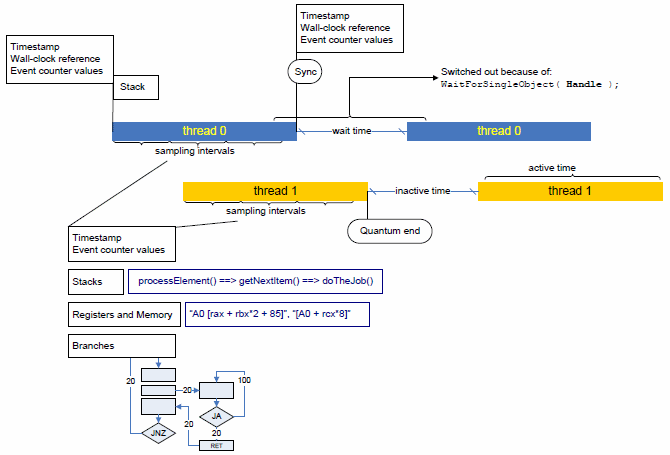
The profiler gains control whenever a thread gets scheduled on and then off a processor (that is, at thread quantum borders). That enables the profiler to take exact measurements of any hardware performance events or timestamps, as well as collect a call stack to the point where the thread gets activated and inactivated.
The profiler determines a reason for thread inactivation: it can either be an explicit request for synchronization (thread 0 calls the WaitForSingleObject function in the example above), or a so-called thread quantum expiration, when the operating system scheduler preempts the current thread to run another, higher-priority one instead.
The time during which a thread remains inactive is also measured directly and differentiated based on the thread inactivation reason: inactivity caused by a request for synchronization is called Wait time, while inactivity caused by preemption is called Inactive time.
While a thread is active on a processor (inside a quantum), the profiler employs event-based sampling to reconstruct the program logic and associate hardware events and other characteristics with the program code. Unlike the traditional event-based sampling, the profiler upon each sampling interrupt also collects:
call stack information
branching information (if configured so)
processor timestamps
All that allows for statistically reconstructing program execution logic (call and control flow graphs) and tracing threading activity over time, as well as collecting virtually any information related to hardware utilization and performance.
Note
Call stack analysis adds an overhead to your data collection. To minimize the overhead incurred with the stack size, use the Stack size option in the custom hardware event-based sampling configuration or -stack-size knob from CLI to limit the size of a raw stack. By default, a full stack is collected. If you disable this option, the overhead will be also reduced but no stack data will be collected.
Analyze Performance
Select the Hardware Events viewpoint and click the Event Count tab. By default, the data in the grid are sorted by the Clockticks (CPU_CLK_UNHALTED) event count providing primary hotspots on top of the list.
Click the plus sign to expand each hotspot node (a function, by default) into a series of call paths, along which the hotspot was executed. VTune Amplifier decomposes all hardware events per call path based on the frequency of the path execution.
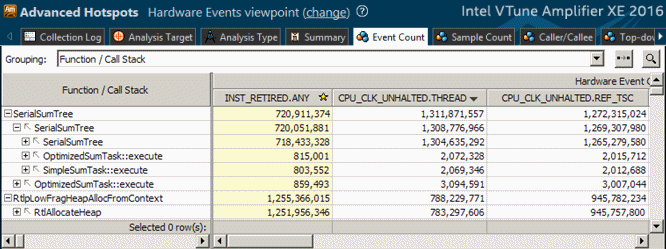
The counts of the hardware events of all execution paths leading to a sampled node sum up to the event count of that node. For example, for the _schedule function, which is the top hotspot of the application, the INST_RETIRED.ANY event count equals the sum of event counts for 7 calling sequences: 22 657 490 276 = 20 377 044 + 5 269 274 +0 + 718 190 701 + 21 857 068 455 + 26 565 167 + 30 019 635.
Such a decomposition is extremely important if a hotspot is in a third-party library function whose code cannot be modified, or whose behavior depends on input parameters. In this case the only way of optimization is analyzing the callers and eliminating excessive invocations of the function, or learning which parameters/conditions cause most of the performance degradation.
Explore Parallelism
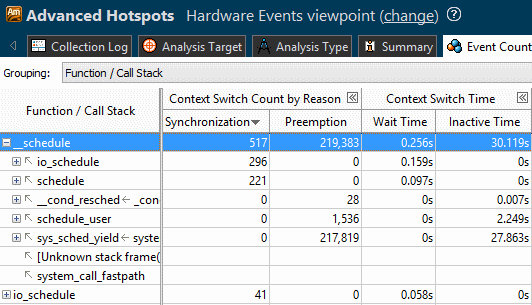
When the call stacks collection is enabled, the VTune Amplifier analyzes context switches and displays data on the threads activity using the context switch performance metrics.
Click the Synchronization Context Switches column header to sort the data by this metric. The synchronization hotspots with the highest number of context switches and high Wait time values typically signals a thread contention on this stack.
Select a context switch oriented type of the stack (for example, the Preemption Context Switches type) in the drop-down menu of the Call Stack pane and explore the Timeline pane that shows each separate thread execution quantum. A dark-green bar represents a single thread activity quantum, grey bars and light-green bars - thread inactivity periods (context switches). Hover over a context switch region in the Timeline pane to view details on its duration, start time and the reason of thread inactivity.
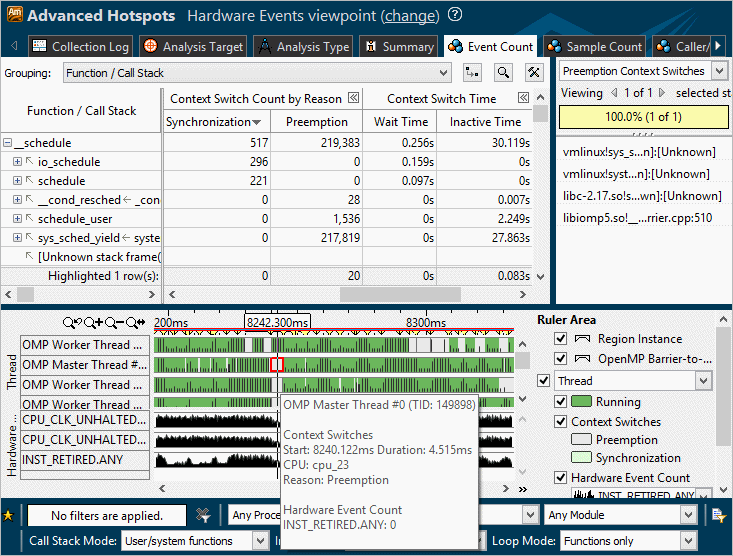
When you select a context switch region in the Timeline pane, the Call Stack pane displays a call sequence at which a preceding quantum was interrupted.
You may also select a hardware or software event from the Timeline drop-down menu and see how the event maps to the thread activity quanta (or to the inactivity periods).
Correlate data you obtained during the performance and parallelism analysis. Those execution paths that are listed as the performance hotspots with the highest event count and as the synchronization hotspots are obvious candidates for optimization. Your next step could be analyzing power metrics to understand the cost of such a synchronization scheme in terms of energy.
Note
The speed at which the data is generated (proportional to the sampling frequency and the intensity of thread synchronization/contention) may become greater than the speed at which the data is being saved to a trace file, so the profiler will try to adapt the incoming data rate to the outgoing data rate by not letting threads of a program being profiled be scheduled for execution. This will cause paused regions to appear on the timeline, even if no pause was explicitly requested. In ultimate cases, when this procedure fails to limit the incoming data rate, the profiler will begin losing sample records, but will still keep the counts of hardware events. If such a situation occurs, the hardware event counts of lost sample records will be attributed to a special node: [Events Lost on Trace Overflow].